Originally the aim of this project was to search two cultural heritage institutions, the Walters Museum and the Brooklyn Museum, to isolate objects on a collection level - specifically manuscripts - and then distill this data on an item level. A script was written in Python for each museum to pull the relevant data. The files are BKM.py and WaltersTest_edit.py.
In each the JSON text string was converted to a Python dictionary. Initially, when working with the data, my particular interest was in the percentage of Persian manuscripts in the both museum’s repositories. Both Walters Museum and the Brooklyn Museum APIs provide access to their digital records of art. After this data was gathered, the next step was to write a counter in the script to help count how many total manuscripts there are in the collection, and how many of these are Persian. For users who are interested in other collection data from these museums, the code for both museums can be modified by changing keywords to search through either institution's holdings. If one wants to search for French manuscripts, as an example, this can be easily done by replacing the existing keywords "Perisan" and "Iran" and inserting the desired keyword.
The resulting information can be viewed on the corresponding graphs, below.
Timelines:
As the project progressed a timeline for each museum - with information obtained from the metadata of the respective scripts of the museums, such as the date made and poets/artists who worked on the object - seemed like a natural fit to visually organize the data. While the samplings were random, I attemped to pull manuscripts from the same time range for both museums - from the 15th century to the 18th century. Further, when possible, I included objects in both timelines from the same poet to highlight the way manuscripts differed aesthetically. For instance, manuscripts containing text from the poet Firdowsi and (in a separate example) the poet Nizami were in the collection of the Walters Museum and in the Brooklyn Museum, and added to the respective timelines. I found the variations interesting and hope it can be a useful resource to compare the holdings of the museums.
Two points to note:
- Each timeline is made up of a random sampling of objects from the respective collections to represent the holdings for each institution.
- Due to the artifactual classification of the manuscripts metadata regarding contributors - poets, caligraphers, and so on- was not available for a few objects.
Graphs:
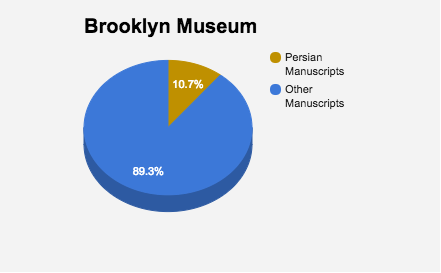
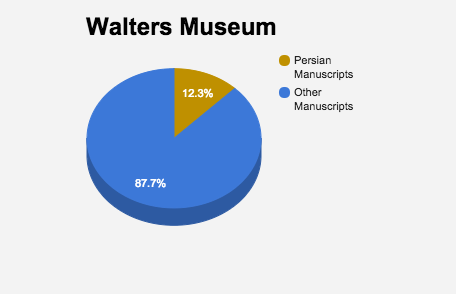
Of interest in my search was the percentage of Persian manuscripts that existed in the overall collection of the Brooklyn Museum and the Walters Museum, respectively. Percentages were calculated from data obtained from my python codes for each museum. While the Walters Museum has a much larger manuscript collection than the Brooklyn Museum, and the former even has an Islamic Manuscript section, the percentage of Persian Manuscripts was nearly the same for both institutions.